이전에 배운 이분 탐색(Binary Search)은 리스트 내에 찾고자 하는 Key 값이 있을 때만 위치를 반환하고 만약 Key 값이 존재하지 않는다면 아무것도 반환을 하지 않았다. 또한, Key 값이 중복된 경우 정확히 우리가 원하는 Key의 위치를 얻을 수가 없었다.
따라서 Key 값이 존재하지 않더라도 Key에 가장 가까운 원소의 위치를 찾아야 하거나, 중복된 Key 값의 범위, 중복 값을 활용하는 등의 문제를 해결하기 위해선 이분 탐색은 한계가 있다. 이를 위해 이분 탐색을 응용한 두 개의 알고리즘이 존재한다. 당연한 말이지만 이분 탐색을 응용하는 알고리즘이기 때문에 리스트는 정렬이 되어있어야 한다.
첫 번째는 Lower_bound라는 알고리즘이다. Lower_bound는 하한선이라는 뜻으로 리스트에서 찾고자 하는 Key 값보다 크거나 같은 첫 번째 인덱스를 찾아주는 알고리즘이다. 이를 활용하면 원하는 Key 값이 없어도 이에 가장 가까운 데이터의 위치를 찾을 수 있다.
Lower_bound는 key 값보다 크거나 같은 원소의 위치를 찾는 것이기 때문에 mid의 값이 key보다 작을 때는 left를 mid + 1로 변경해 주고 key보다 크거나 같을 때는 right를 mid로 변경하여 key 값을 포함시키도록 한다.
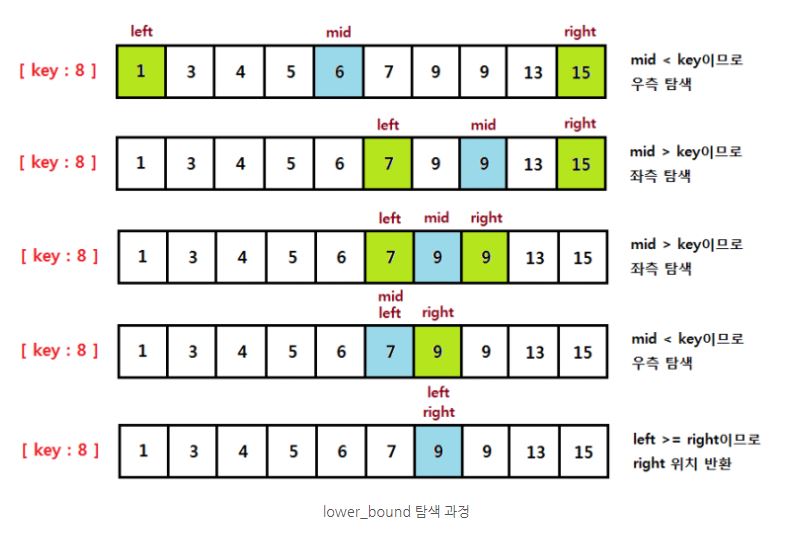
Lower_bound를 Java로 구현한 코드는 다음과 같다.
public class Blog {
public static void main(String[] args) {
int[] list = {1,3,4,5,6,7,9,9,13,15};
System.out.println(lower_bound(8, 0, list.length-1, list));
}
public static int lower_bound(int key, int left, int right, int[] list) {
int mid;
while (left < right) {
mid = (left + right) / 2;
if (list[mid] < key) left = mid + 1;
else right = mid;
}
return right;
}
}
두 번째는 Upper_bound라는 알고리즘이다. Upper_bound는 상한선이라는 뜻으로 리스트에서 찾고자 하는 Key 값보다 큰 첫 번째 인덱스를 찾아주는 알고리즘이다.
Upper_bound는 key 값보다 큰 원소의 위치를 찾는 것이기 때문에 mid의 값이 key보다 작거나 같을 때는 left를 mid + 1로 변경해 주고 key보다 클 때는 right를 mid로 변경하여 key 값을 포함시키도록 한다. 즉, key를 찾아도 left를 증가시켜준다.
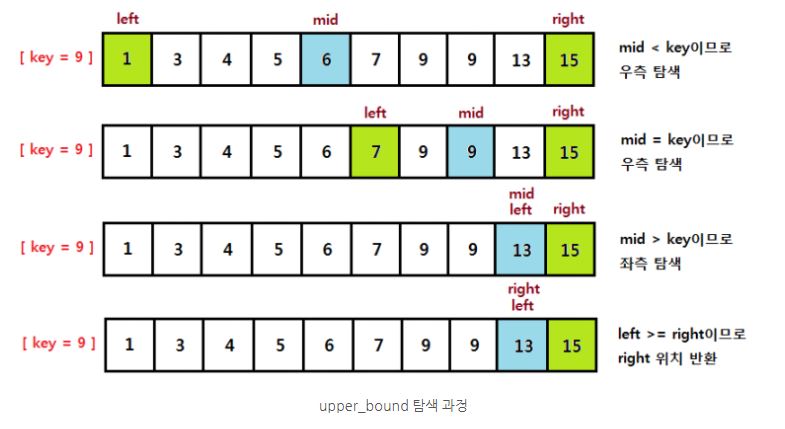
Upper_bound를 Java로 구현한 코드는 다음과 같다.
public class Blog {
public static void main(String[] args) {
int[] list = {1,3,4,5,6,7,9,9,13,15};
System.out.println(upper_bound(9, 0, list.length-1, list));
}
public static int upper_bound(int key, int left, int right, int[] list) {
int mid;
while (left < right) {
mid = (left + right) / 2;
if (list[mid] <= key) left = mid + 1;
else right = mid;
}
return right;
}
}
'Computer Science > 알고리즘' 카테고리의 다른 글
| 너비 우선 탐색(Breadth First Search) : BFS (0) | 2021.07.02 |
|---|---|
| 깊이 우선 탐색(Depth First Search) : DFS (1) | 2021.07.02 |
| 이분 탐색(Binary Search) (0) | 2021.07.02 |
| 기수 정렬(Radix Sort) (0) | 2021.07.01 |
| 힙 정렬(Heap Sort) (0) | 2021.07.01 |




댓글